
Migrate your infrastructure to AWS in an optimal way
The Cloud appears to be an Eldorado for many companies: simpler application deployment, cost reduction, use of innovative technologies, so many advantages that Amazon promises to its potential customers, but is it that simple?
AWS, and the cloud more generally, can be an excellent lever on the points mentioned above, however it is quite easy to lose feathers. In this article, I will list what, for me, seems to be the mistakes to avoid.
Think Different
I'm not an Apple fan, but I really like this slogan. Going into AWS requires you to think differently about your infrastructure. The lift and shift policy rarely pays off.
In addition to the fact that it is necessary to adapt to certain Amazon paradigms, it is also necessary to train its teams to think differently about infrastructures, in a universe where a lot of data is not persistent, how to create efficient infrastructures?
Having the right tools for deployment
Amazon makes it very easy to deliver new applications, or application versions, however, if you want to avoid driving everything by hand, the main interest of the cloud is that everything is API. This means that deployments can be fully automated using the right tools.
At this point, there are two solutions, either you already have a powerful tool, which you can connect to Amazon, or you are moving towards adapted tools.
I consider that you need at least 2 complementary tools to serenely pilot an Amazon deployment.
First of all, it is necessary to have an infrastructure tool as code, which allows you to describe the desired deployment via scripts. This is what allows you to use classic versioning tools such as Git for example, the infrastructure becomes a versionable element, in the same way as any of your applications.
On this side, I see at least 2 tools adapted to this need on AWS :

- CloudFormation (lien) : The AWS tool to make AWS. The first advantage is that it is fully integrated with Amazon. It is kept up to date by AWS, and does not require any infrastructure to operate, it has no cost, other than the cost of the elements it deploys. Using CloudFormation also allows you to take advantage of AWS support on deployments.

- Terraform (lien) : Open source infra as code tool, with a growing community. HashiCorp is an editor specialized in continuous deployment. The main advantage of Terraform is the multicloud, it is possible to deploy in parallel an infrastructure on several clouds, and even on VMWare for example. In contrast to CloudFormation, Terraform needs a dedicated infrastructure to function.
Then, it is very useful to have a GUI to monitor these deployments and to be able to automate them, for example when a new application version is available. In my opinion, Jenkins is still the best solution for this, especially since the application is often already present in the company.
- Jenkins (lien) : Jenkins is an open source automation server. It has a huge community that contributes to its continuous improvement. It allows to automatically trigger treatments on certain events as well as to follow and pilot actions from a centralized GUI. For workloads requiring load, it can also run in a master/slave model.
It is completely possible to go to Amazon without these tools, however, one must be aware that this makes deployments much more complex, as well as the monitoring of deployed infrastructures.
Asking the right questions about your application
Going to the cloud also requires asking the right questions to optimize its deployment:
- Is my application under constant load?
- Does my application need to run 24/7?
- Can my application evolve (or do I have the budget to do so)?
These questions allow us to design the most adapted and least expensive architecture.
The question of machine load and 24/7 operation
Amazon allows the deployment of elastic infrastructures. In reality, what do we gain?
Let's say I want to deploy an infrastructure for a classic website: a load balancer, several backends and a database, all with high availability.
Similarly, let's assume that I know that each application server can support 150 connections/second, and I have variations on the number of users ranging from 100 connections/second to 1500 connections/second.
If we follow the on premise model, then we will provide an architecture that can support 1500 connections per second.
This results in something like the following (I arbitrarily chose m5.large instances):

Global cost: 1092$ monthly
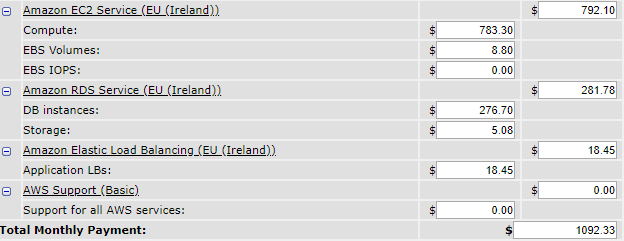
My app will hold the load, however, I don't really understand what I get out of going on Amazon right now...
It's normal, if we follow this example, our resources regularly run at less than 20% of their performance, however, we pay 100% of their cost.
In the graph below, I've indicated (in an equally arbitrary way) the number of connections, as well as the number of associated servers needed.
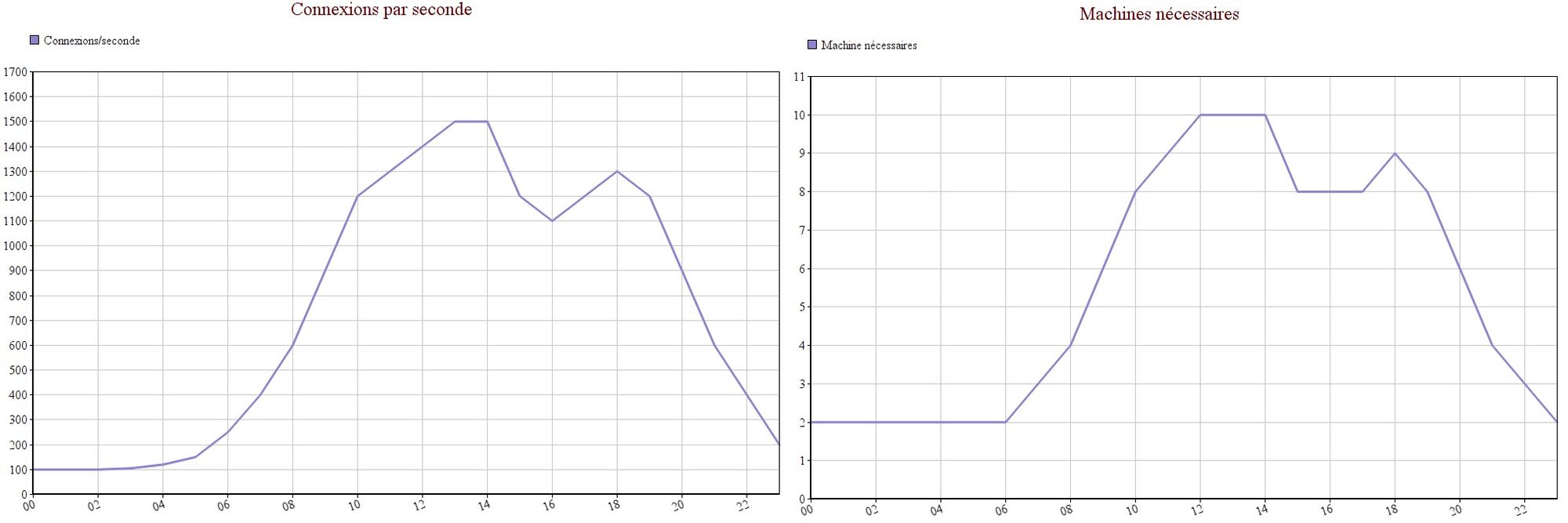
We can see that very often we don't need the 10 active machines. This is where the use of autoscaling groups comes into play. By using autoscaling groups, the idea is to stick as close as possible to the need, by automatically starting and stopping machines under certain conditions. By redoing the same estimation, in a very simplistic way (without taking into account the start/stop time of the machines for example), it represents a saving of more than 30%!
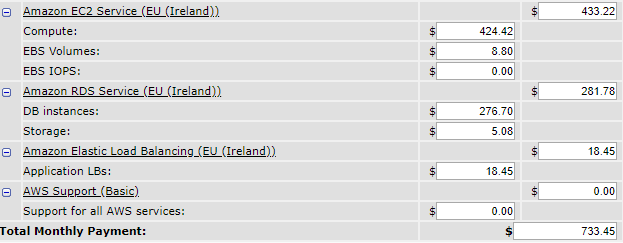
Think FinOps as much as possible
FinOps is about optimizing costs, but not simply by being stingy at the lowest cost that seems high, but by having complete visibility of those costs. How do you do it?
Use tags
On Amazon, it is possible to tag your machines to filter them, but these tags can also be used in Cost explorer, which allows you to track costs on Amazon. The interest is to know directly the projects associated with each infrastructure as well as their costs.
Pooling resources
Each project may not need to be completely autonomous, and some resources can probably be shared. For example, it may not be necessary to have enterprise support on all your AWS accounts. Similarly, some resources, although not paid for, can be easily shared, such as security group and mail order for example, simplifying MCO costs at the same time.
Get support
AWS is a very interesting environment, but as I often say: "On Amazon, there are 300 ways to do the same thing, not all of them are suitable". Small problem, to know the adapted solution, you have to have enough hindsight to know the alternatives. It takes a long time to become proficient on Amazon, especially since a large part of the work consists of monitoring technology, given the number of announcements made almost daily.
This post is finished, it is not intended to be exhaustive, but simply to highlight what I learned from my experience on the Amazon cloud.


Comments ()